Opinions

Designing Agentic AI Through Modular System Architecture
Explore how to build dependable agentic AI using modular system design, deterministic workflows, context encapsulation and verb-driven agents. A practical guide to architecting stable, secure, production-grade AI systems.


When we started building “agentic” systems, the AI hype made autonomy sound like it was just a few prompts away. The professional world was full of flowcharts—along with their planners, orchestrators, evaluators—all wrapped around a large language model that supposedly could reason, plan and act independently.
Like most everyone else in the industry, Backstroke began exploring and building our own agents. After a few proofs of concept and demos, we were surprised by how fragile these approaches really were.
These systems didn’t operate autonomously. They operated erratically. Prompts broke, loops stalled and we spent more time watching the model than letting it work. It wasn’t that the models were bad. In fact, they were doing exactly what they were designed to do. The problem was how we were designing around them.
We were asking the model to do too much: to reason, plan and execute in a world where only one of those three is its natural strength. Taking a step back, we decided to approach it from a different angle. Contrary to all the hype, instead of trying to wrap everything in AI, we started asking ourselves “Does it really make sense to use it here?”
That’s when it clicked. The hype said “AI can do it all,” but we realized it should be used as a tool, not as the system itself.
What follows isn’t a universal blueprint for AI systems, but rather, what’s worked for us. These are some of our takeaways shaped by real experiments, broken pipelines and lessons learned the hard way. They’re not claims about how all AI should be built, but reflections on how we’re learning to make AI reliable in production for your brand.
Turning Point: Breaking the Monolithic Agent Architecture
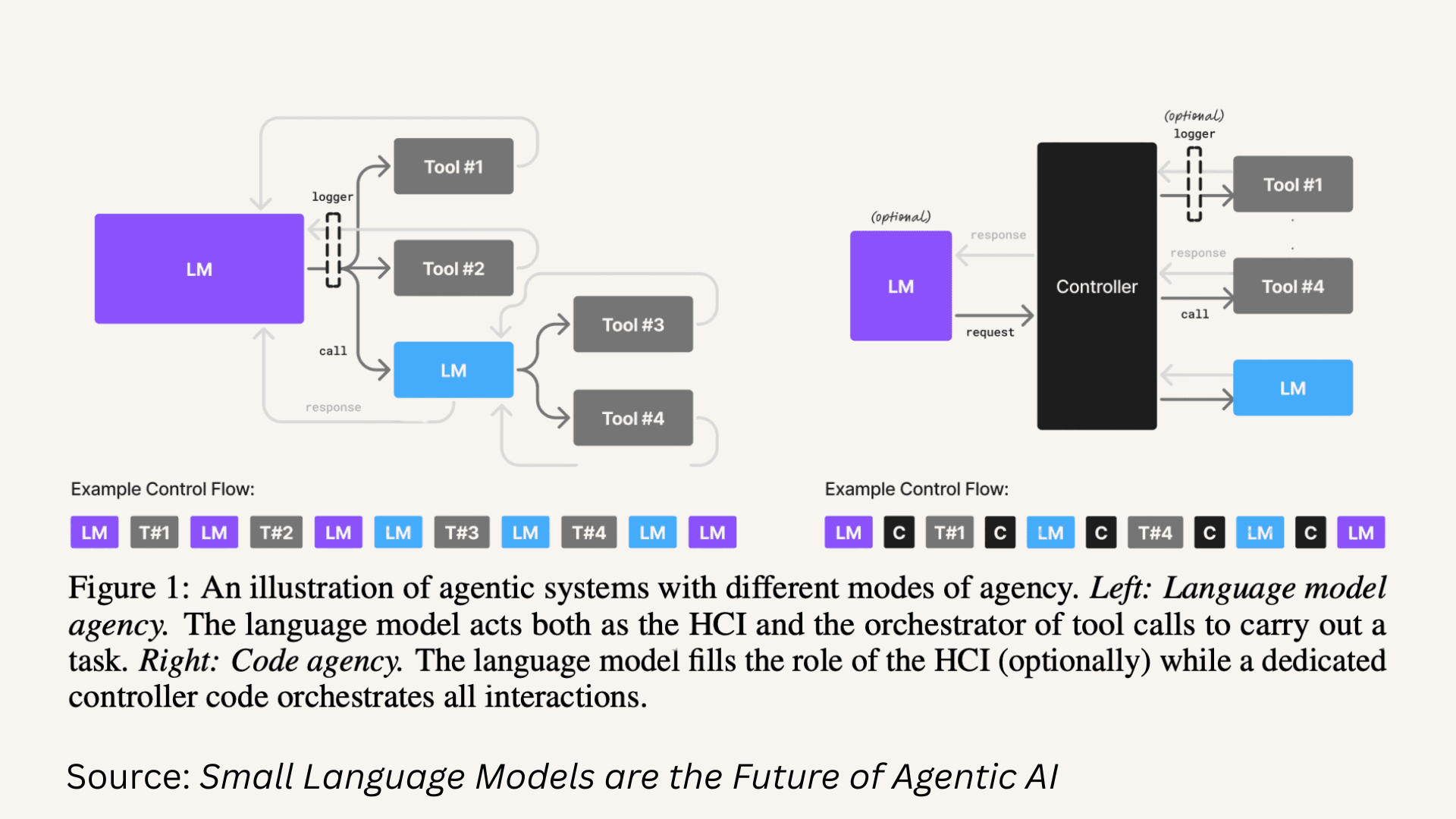
There are two broad paths for integrating “agency” into a system: one where the model itself drives the process (Language Model Agency) and one where the codebase carries the structure and the model fills in the semantic gaps (Code Agency). On paper, both approaches promise similar outcomes. In practice, only one of them held up. Every time we pushed these systems, the code-driven approach consistently proved more stable, more predictable and—ironically—more flexible.
One of the first places we saw this play out was our product-extraction pipeline. That’s the foundation that lets Backstroke understand product catalogs and generate campaigns for thousands of brands. Originally, we built this as a single “smart” agent. It used tools to crawl brand sites, reasoned about the layout, found product details and transformed its findings into structured data. One model, one endpoint. Simple enough.
Except it wasn’t.
Every new site added more complexity. The prompt grew, the logic drifted and the system became unpredictable. It was trying to be universal when it needed to be local. Each time we improved one edge case, we broke another.
So we started over.
Instead of one all-knowing agent, we built a chain of smaller, deterministic components. One transforms HTML into Markdown. Another identifies relevant information like names, prices or images. And one more transforms that data into structures we can actually use.
Each component sees only what it needs. Each output is deterministic and composable. The model still plays a role, but a focused one, reasoning only where classical code can’t.
The effect was immediate. Accuracy went up. Failures became explainable. Testing became possible again. Autonomy emerged not because we “gave the model more tools / control,” but because the system was designed clearly enough to handle uncertainty without falling apart.
Model Limits: Separating Probabilistic Reasoning From Deterministic Control Flow
A lot of AI hype quietly assumes we’ve already reached AGI, believing that today’s models can reason, plan and act like general-purpose intelligences. That assumption is wrong. Models don’t “understand” the world in a human sense, and they can’t manage open-ended reasoning chains or long-term objectives without help.
What they can do—and do exceptionally well—is understand meaning. They excel at classification, labeling, summarization and semantic translation. They turn messy information into structured understanding. But when you ask them to manage state, remember context over time or execute multi-step logic, they start guessing. They reconstruct context probabilistically with every prompt.
We had to stop pretending they were systems.
They’re probabilistic engines that can infer and interpret, not state machines that can control. Once we separated those two roles, everything became simpler.
The model’s job became evaluating semantics. The system’s job became acting.
That principle shaped how we design everything from product understanding to email generation. We give models the freedom to think and systems the responsibility to execute. That separation reduces complexity and improves accountability. We can test and observe deterministic behavior without worrying about whether a random temperature spike derails a workflow.
It’s not that autonomous-capable systems shouldn’t exist. They can, but only inside clear boundaries. The model’s “freedom” is always bounded by the interface: a web page, an editor, a command set. The model can make decisions, but only within those walls.
The Context Problem: Mitigating Context Bloat Through Encapsulation
When people talk about improving model performance, they often think, “just give it more information.” But more context doesn’t mean more intelligence. It means more noise. Every extra variable, example or rule increases the model’s cognitive load, forcing it to guess which parts actually matter.
In the industry, this is referred to as context bloat, the silent performance killer of most “intelligent” systems.
There are a number of solutions to this problem but we decided to look at it differently. To us, the solution wasn’t new; it just had a new name. Context engineering is really just what software engineers know as encapsulation. Encapsulation keeps components of an application from knowing too much so that the whole system stays clean and predictable. The same logic applies here: limit what each agent sees, and its reasoning sharpens.
We realized every agent should have a single responsibility and a well-defined boundary. Expanding its scope didn’t make it smarter, but instead more fragile. Once we began enforcing that separation, results stabilized across every layer of the stack—from extraction to generation to campaign assembly.
Small Agents, Clear Interfaces: Designing Single-Responsibility, Verb-Defined Agents
The question then is, how small should we make the agents?
The rule of thumb we use is to boil tasks down into verbs and then see which verbs overlap. For example, if we had a “product context agent” who’s responsible for gathering product information, we need to separate this out into verbs. There’s “Fetch product page”, “extract relevant pieces”, “transform to JSON.” Fetch is deterministic so we don’t need an LLM for this, but extract and transform are both semantic tasks, so we can create agents for each of these.
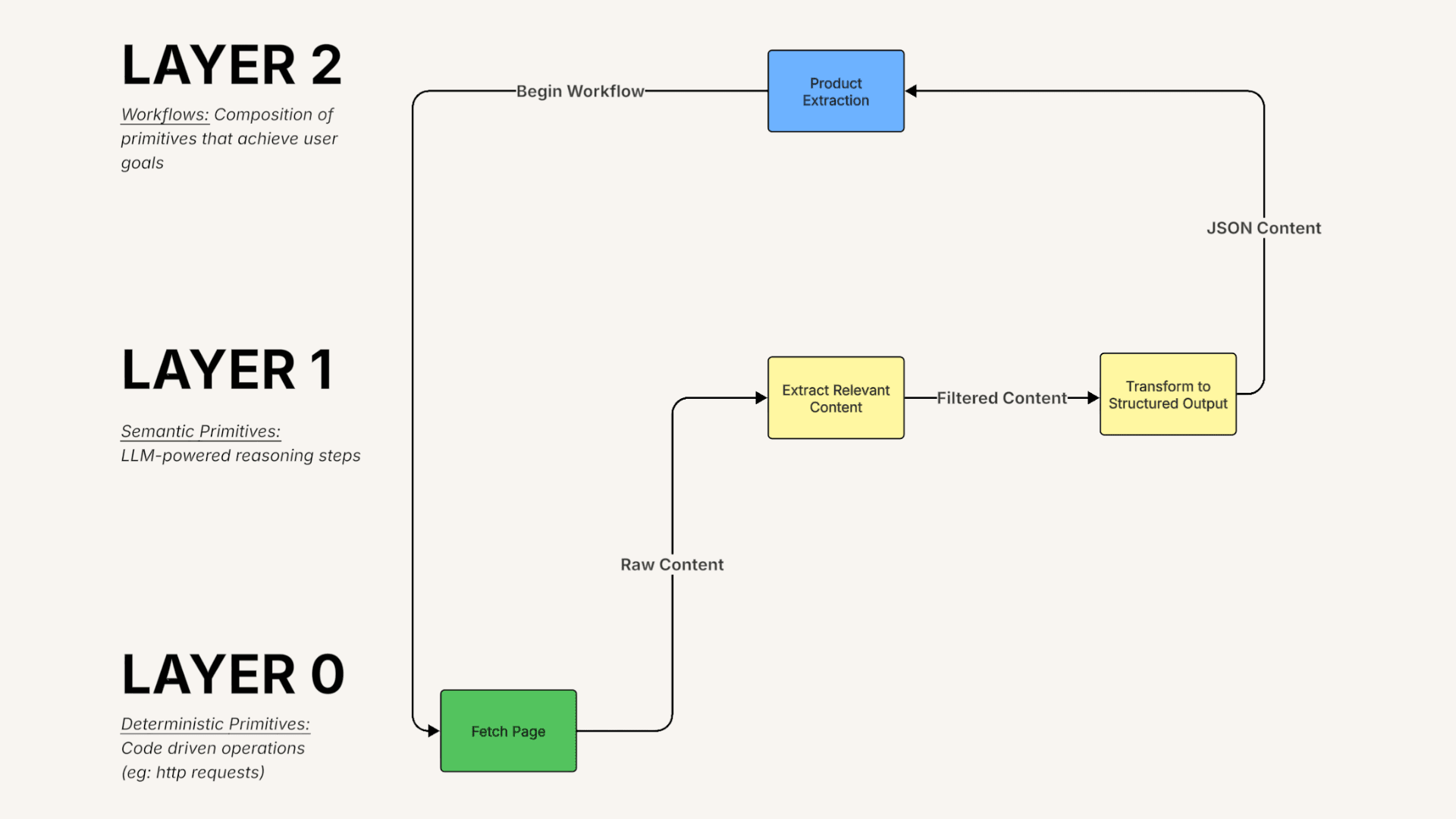
We think about system prompts in the same way we think about classical software engineering interfaces. It describes the task itself. So, for the sake of this example, the “transform” agent could be used in many different areas, so we’d focus on defining what the act of “transforming” looks like and mention key items that the model should pay attention to in the user prompt
Now, many people react to this idea poorly because it appears as if we’re stripping away the flexibility from the agents. Most times though, it’s the opposite. While the architecture has some effect on flexibility, the actual interface that exposes the agent has a much higher effect.
If an agent lives inside a UI, its autonomy is bounded by what the user can express through it: inputs, buttons, structured forms.
If it lives behind an API, it’s constrained by schemas and contracts.
If it operates within a workflow, it can only act within the steps that surround it.
That boundary is what keeps intelligence predictable. It’s the difference between a creative assistant and a rogue process.
At Backstroke, those boundaries are what let us safely combine reasoning and automation at scale; where models make creative, data-driven decisions, but the system ensures every one fits brand, tone and strategy.
Most of the time, the right move isn’t to make the model smarter. It’s to make the interface clearer. When intent is captured precisely, autonomy becomes predictable.
Security & Reliability: Emergent Benefits of Least-Privilege, Encapsulated Agents
Designing this way made us realize something else. When the structure is right, safety happens naturally.
Each agent has just enough authority to do its job and nothing more. If something fails, the scope of failure is tiny. You don’t need complex permission layers or endless guardrails. The architecture itself enforces least privilege.
That’s the beauty of small, composable systems. They’re self-contained. Risk can’t spread, because context doesn’t.
Security, reliability and explainability all come from the same principle: localized intelligence and deterministic action. So don’t build walls around the model. Shape the system so that intelligence stays in the right places.
Conclusion: Reliable AI Comes From Clear Boundaries, Not Bigger Models
After building and breaking these systems, one theme stands out. Reliable AI isn’t about giving models more freedom, but giving systems more structure.
Language models already reason better than any rule engine we’ve ever built, but they still need rails. The autonomy we want doesn’t come from letting them act unchecked. It comes from designing the boundaries that make their reasoning useful.
That’s how Backstroke ships AI that’s both creative and consistent, with models that reason freely within clearly defined systems that ensure predictable outcomes for your brand.

